ABC and Rcpp
Michael Lerch
Model and Likelihood
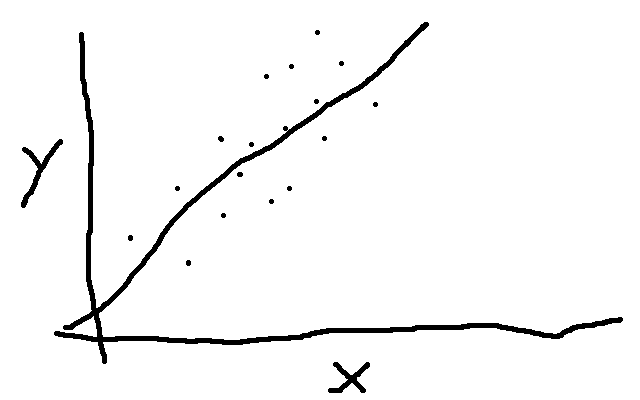
\[y = m * x + b\]
\[\mu = m * x + b\]
Likelihood
\[y = \mu + \epsilon\]
\[\epsilon \sim N(0, \sigma)\]
Prior

\[P(\theta)\]
Prior -> Posterior
\[P(\theta | Y)\]
Prior -> Posterior
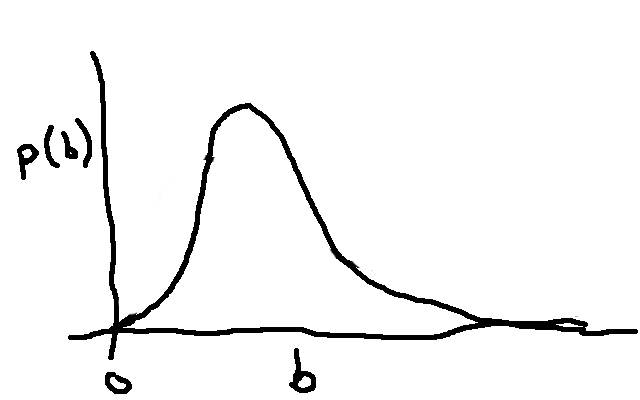
\[P(\theta | Y)\]
Using the posterior
curve(dnorm(x), xlim = c(-3, 3)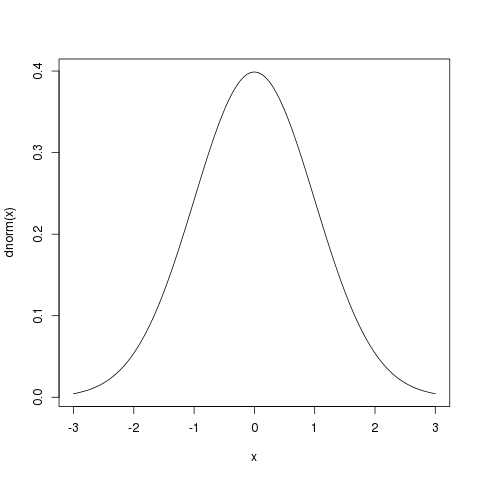
plot(density(rnorm(1000)), xlim = c(-3, 3))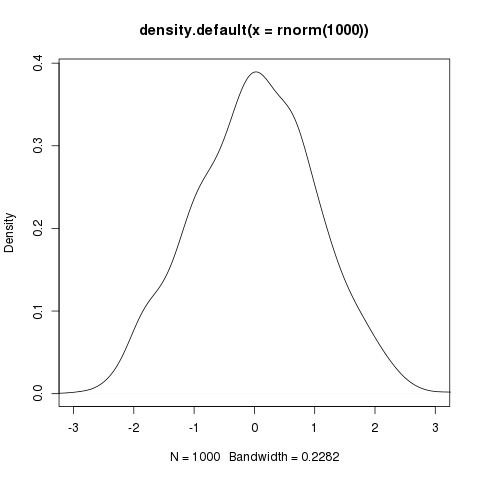
“Rejection sampling”
Sample from the joint distribution, \(P(\theta, Y) = P(\theta)P(Y|\theta)\)
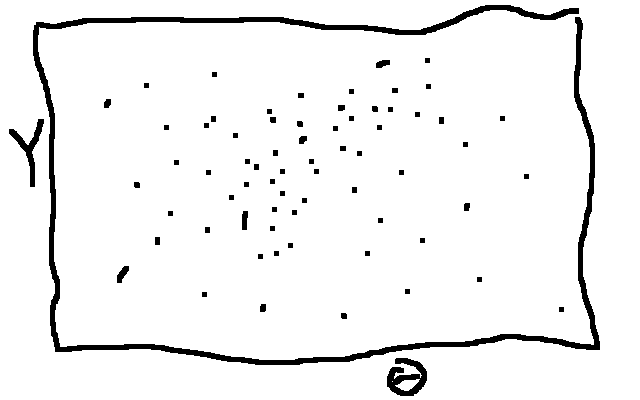
“Rejection sampling”
Reject when the sampled \(Y\) does not equal the observed
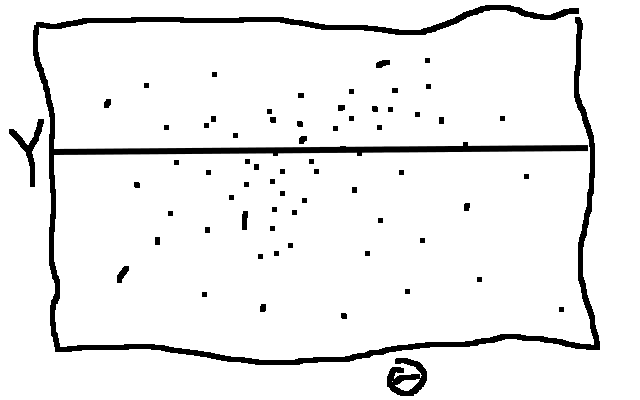
uspop data in R